 An Introduction to XML
An Introduction to XML
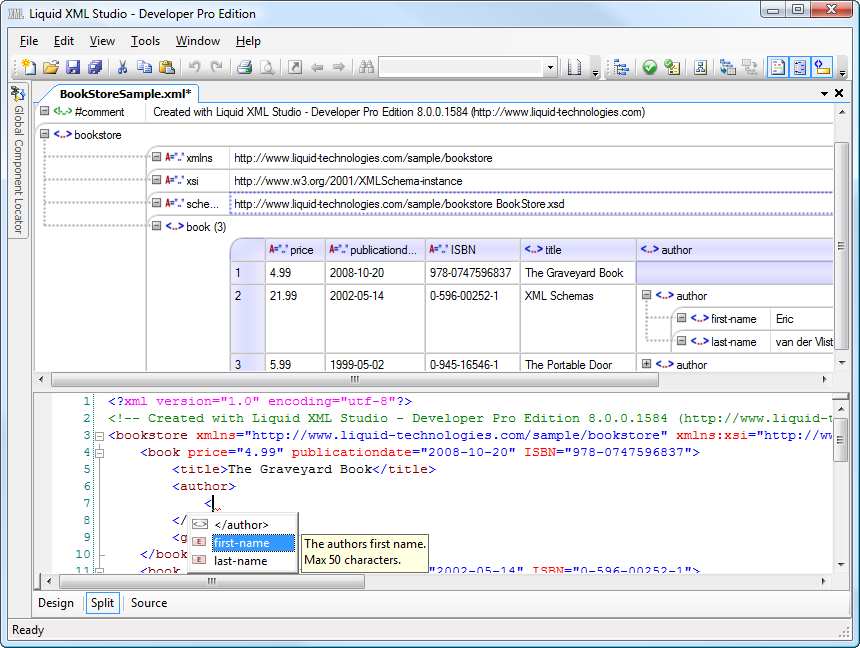
An Introduction to XML
This tutorial answers some basic questions when starting to author your first XML Document.
What is XML?
XML is a general purpose mechanism for describing hierarchical data. Data items are contained within elements and attributes. Elements can contain textual data, attributes and other elements, attributes can just contain textual data.
Whenever there is a need to store complex data, whether it is for passing between systems or storing in a file, the data must be marked up in some way. When it is read back in, it needs to be possible to tell were one record ends and another begins, and which record is contained within another. It was this gap that XML filled.
Whenever there is a need to store complex data, whether it is for passing between systems or storing in a file, the data must be marked up in some way. When it is read back in, it needs to be possible to tell were one record ends and another begins, and which record is contained within another. It was this gap that XML filled.
Prior to XML, developers would produce their own proprietary formats for storing data, with varying levels of success. It's not difficult to conceive of your own system for representing data, but you would also have to write your own custom parser and serializer which may be a complex and error prone task. XML provides a general mechanism for marking up and representing data. As XML is now a wide spread standard, various other tools and technologies are available on most platforms. Using XML will make it possible for you to take advantage of may other XML aware technologies such as XPATH, DTD, XSLT, XSD, XQUERY, and XML Data Binding.
One complaint about XML is that its verbose, and consumes to much space. These days disk space is cheap, and its typically better to have readable data, however there are a few occasions were this is a concern and these are typically addressed using an XML compression technology such as Fast Infoset.
XML Example
<?xml version="1.0" encoding="UTF-8" ?>
<book isbn="0123-456-789">
<title>The Lion The Witch and the Wardrobe</title>
</book>
In the example "book" and "title" are elements, and "isbn" is an attribute. The first line is the XML header which defines the character encoding.
Well Formed XML (Valid XML)
Well formed means that all the tags match up. In the example above we opened a "book" element on line 1, and closed it on line 3. Without line 3, the "book" element is not closed, and thus the document is not well formed. Also an attribute must have a closing quote (note the standard allows either single or double quotes to be using for attributes, as long as they are the same at the start and the end of the attribute, i.e. isbn="...." or isbn='....' but no isbn="....'
Escaping control characters
If the textual data within and element needs to contain a < or > character, then this must be escaped in order to prevent it being confused with an element marker. This is done by replacing it with the literal < or > respectively. This introduces a problem when trying to use the & character, so this is escaped using the & literal. Similarly in an attribute, the quote " character must be escaped using " and ' using '
- & (& or "ampersand")
- < (< or "less than")
- > (> or "greater than")
- ' (' or "apostrophe")
- " (" or "quotation mark")
International Support
The first line of an XML Schema is the XML header. This has an optional "encoding" field which describes how the rest of the document should be interpreted (i.e. how to map the data in the file into characters). The standard formats when dealing with international characters are utf-8 and utf-16, character encoding is a whole separate topic, but if you are using an XML Editor (like Liquid Studio, then this is all taken care of automatically).
Reading XML Data Programmatically
DOM (Document Object Model)
A DOM parser is an XML parser that reads XML data and stores it in a set of objects, these objects can then be examined and the data extracted from them. The structure of the DOM objects is standardized by the W3C, so the code for reading XML is more or less standard across multiple platforms.
One of the drawbacks of a DOM parser is that the whole XML document has to be read into its object form (and thus into system memory) meaning it is not possible to deal with very large XML files.
DOM parsers exist for all the main platforms and languages, and are typically built into the platforms core framework.
SAX (Simple API for XML)
A SAX parser is more primitive XML reader. For every entity it reads in the XML data, it fires an event (or callback) which the consuming application must deal with or ignore. This basic interface makes it possible to cope with arbitrarily large XML files, as the consuming application need only store its current state, discarding information that has already been read, when it's no longer needed. It does however complicate the handling of the data, as the application must keep track of its state (i.e. position in the XML document).
Typically this technique is combined with a DOM parser. The application keeps track of its position in the XML until it comes across a chunk of data it needs to deal with, it then constructs a DOM tree based on a small section of the whole XML document, processes the DOM tree and discards it before moving on.
XML Data Binding
XML Data Binding is similar to the DOM mechanism. The XML document is read into a set of objects, however instead of being read into a set of general purpose DOM objects, its read into a set of classes generated specifically to deal with the type of XML document being read. These classes are generated using an XML Schema which knows about the shape of valid XML documents.
This mechanism makes it much easier for developers to work with XML data, as they are dealing with strongly typed objects (i.e. they have names and properties that reflect the elements and attributes in the XML data).
This technique must also read the entire XML Document into memory (as with DOM), but this restriction can be worked around, see Liquid XML Data Binding - dealing with large files.
There are a number of tools for XML Data Binding, Liquid Studio provides a solution that generates classes for C#, C++, Java, VB.Net & Visual Basic.
XML Schemas
An XML Schema formally specifies the structure of an XML document. This has a number of uses:
- Validation - The XML Schema can be used to validate an XML document, to ensure that it contains all the correct data in the correct places.
- Interoperability - Because the shape of the XML Document is described formally there is no ambiguity, meaning that each team working with a given XML Schema know what the resulting XML document must look like, there are no ambiguous specifications to work from.
- Code Generation - The XML Schema can be used to generate code that will allow developers to read and write XML data using strongly typed classes. Meaning developers just have to work with simple objects with strongly typed properties. This technique is known as XML Data Binding. Liquid Studio provides XML Data Binding for C#, C++, Java, VB.Net & Visual Basic.
- Visualizations - It is possible to show the structure of an XML Schema Graphically making it easier for developers to understand.
- Documentation - An XML Schema can contain documentation, which can be generated into a convenient human readable form, see XML Schema Standards Library

There are a number of mechanisms for describing an XML Schema.
- DTD (Document Type Definition) - the original standard, defined within the W3C's XML standard. The DTD standard is all but obsolete now, replaced by the W3C's XSD standard. DTD's have their own format, can define substitutions internally within themselves, requiring multiple parses to extract the normalised document. They were also quite limited, allowing course validation, and minimal re-use.
- XDR (XML-Data Reduced) - a standard developed by Microsoft that bridged the gap between DTD, and XSD schemas. A parser was implemented in MSXML up to version 6 when it was dropped. It was also used to describe data in older versions of Biz Talk. The document was described in terms of XML, and was very simplistic, offering minimal validation or reuse, but was simple to parse and extensible.
- XSD (XML Schema Definition) - ratified by the W3C, it is now the de facto mechanism of describing XML documents. It allows for complex validation, re-use via inheritance and type creation, is described in terms of XML, so is easy to parse, and has support on most platforms. Almost all major data standards are now described in terms of XSDs.
- RELAX NG (REgular LAnguage for XML Next Generation) - RELAX NG is relatively simple structure, and shares many features with the W3C XSD standard, data typing, regular expression support, namespace support, ability to reference complex definitions. Open source parsers exist on most platforms, but it is not widely used.
Reference
Tools for Designing and Developing XML Schemas Free Trial
More XML Tutorials
Online Tutorials
- Document Type Definition (DTD)
- XML
-
XML Schema (XSD)
- XML Schema (XSD) Tutorial
-
XML Data Binding
- XML Data Binding Tutorial
- XML Data Binding Examples
- XPath